AI を借りる vs 所有する:RTX 4070 Ti Super で動かした初めてのローカル LLM
数週間、私の AI は「レンタル」だった——プロンプトは海の向こう、他人のデータセンターへ。今週、それを自宅に持ち帰った。
ここ数週間、私と人工知能の関係は「レンタル」だった。Claude にログインし、遠いデータセンターのサーバーにプロンプトを送り、答えが海を渡って戻るのを待つ。便利だが、根本的な何かが欠けている:自律性だ。
だから今週、借りるのをやめて所有することにした——本物のモデルを、自分のマシンで、自分のシリコンで、自分の電気で、クラウドを介さずに走らせる。
レンタルか、所有か
決断 · 便利さより自律性知能を借りるのは簡単だ。タブを開き、打ち込めば、答えが魔法のように現れる。だがどの言葉も、決して見ることのないハードウェアへ届き、自分が定めたわけではない上限と規約に支配される。便利さは本物だ——そして依存もまた本物だ。
所有するとは、モデルが自分のディスクに住み、自分の部屋で答えること。海を越える往復もなく、アカウントもなく、裏で回り続けるメーターもない。客から主人へのこの転換こそ、この実験の全目的だった。
私の秘密兵器
スペック · ボトルネックは VRAMAI をローカルで動かすと決めたとき、最大のボトルネックは CPU でも RAM でもない——VRAM(ビデオ RAM)だ。大規模言語モデルは巨大な数学的構造で、人が読める速度で答えさせるには、GPU のメモリの中に住まわせる必要がある。
最先端のゲームが好きなおかげで、私は幸運にも NVIDIA RTX 4070 Ti Super を使っている。エンタープライズ級の A100 ではないが、私にとってすべてを変えた決定的な特徴がある:16GB の VRAM だ。
「これだ!」の瞬間:Gemma を走らせる
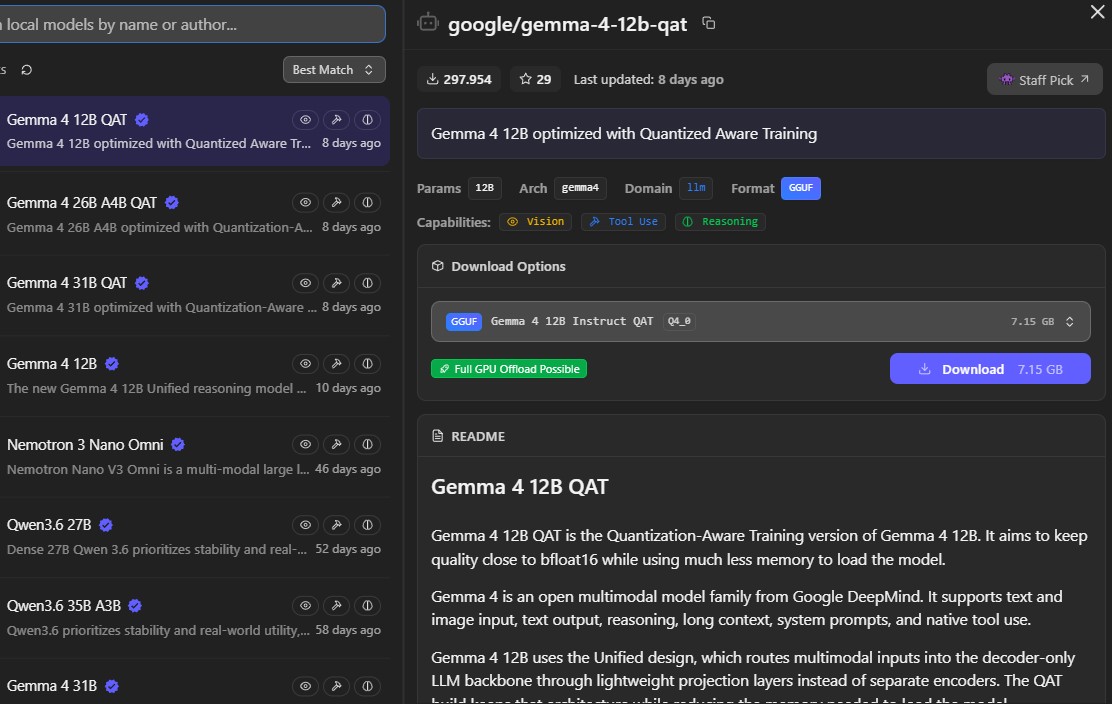
実行 · 16GB に Gemma-26B(a4b)旅が私にとって「本物」になった瞬間は、Gemma-26B(a4b バリアント)を 4070 Ti Super に無事読み込んだときだった。この規模のモデル——260 億パラメータのモデル——をコンシューマー機で動かすのは、魔法のように感じる。
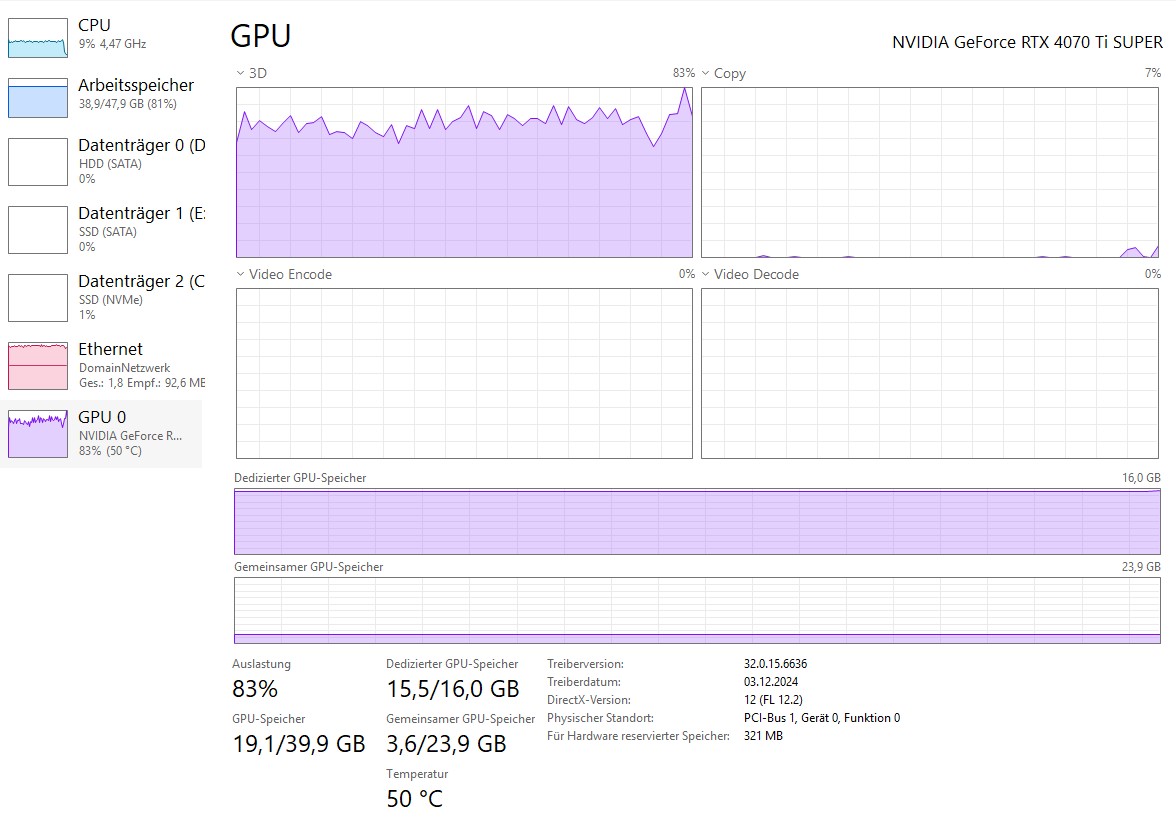
モデルが量子化(圧縮)されている仕組みのおかげで、16GB の VRAM 上限にぴたりと収まる。テキストが画面を流れていくのを、まったく自分の電気と自分のシリコンだけで動かしながら眺めたことは、視点の深い転換だった。
第三者に送られるデータはない。利用上限もない。サブスクの階層もない。あるのは私と、私の GPU と、モデルだけ。
ある種の安心
保持 · データは自分のディスクにローカルでホストすることには、ある種の安心がついてくる。次の世代を訓練するために第三者企業へ送られるデータは一切ない。「利用上限」も「サブスクの階層」もない。あるのは私と、私の GPU と、モデルだけだ。
道具との関係が違う——サービスを借りるというより、楽器を所有するのに近い。重みが一度ディスクに載れば、インターネットは任意になる。
まだ学びの途中
学ぶ · 量子化、コンテキスト、VRAMこの分野では、私はまだ大いに学びの途中だ。量子化(モデルをどう縮めるか)、コンテキストウィンドウ(モデルがどれだけ覚えていられるか)、そして大きな重みを限られた VRAM に収める繊細なバランスを学んでいる。
目的は、机の上に格好いい技術デモを置くことではない;本当に自分が所有する、私的で知的なアシスタントを作ることだ。
まともな VRAM の GPU があるなら、助言は単純だ:LM Studio をダウンロードし、モデルを見つけ、遊び始めること。クラウドは素晴らしい——だが本当の自由はエッジにある。