KI mieten vs. besitzen: Mein erstes lokales LLM auf einer RTX 4070 Ti Super
Wochenlang war meine KI „gemietet“ — ein Prompt über einen Ozean ins Rechenzentrum eines anderen. Diese Woche habe ich sie nach Hause geholt.
In den letzten Wochen war mein Verhältnis zur Künstlichen Intelligenz „gemietet“. Ich logge mich bei Claude ein, schicke einen Prompt an einen Server in einem fernen Rechenzentrum und warte, bis die Antwort über den Ozean zurückreist. Es ist bequem, aber es fehlt etwas Grundlegendes: Autonomie.
Also beschloss ich diese Woche, das Mieten zu beenden und zu besitzen — ein echtes Modell auf meiner eigenen Maschine laufen zu lassen, meinem eigenen Silizium, meinem eigenen Strom, ohne Cloud im Spiel.
Gemietet vs. besessen
Entscheiden · Autonomie vor BequemlichkeitIntelligenz zu mieten ist leicht. Du öffnest einen Tab, tippst, und die Antwort erscheint wie von Zauberhand. Aber jedes Wort reist zu Hardware, die du nie sehen wirst, geregelt von Limits und Bedingungen, die du nicht festlegst. Die Bequemlichkeit ist echt — und die Abhängigkeit auch.
Besitzen heißt, das Modell lebt auf deiner Platte und antwortet in deinem Zimmer. Kein Hin und Her über den Ozean, kein Konto, kein Zähler, der im Hintergrund läuft. Dieser Wechsel, vom Gast zum Gastgeber, war der ganze Sinn des Experiments.
Meine Geheimwaffe
Spec · der Engpass ist VRAMWenn du dich entscheidest, KI lokal laufen zu lassen, ist dein größter Engpass nicht die CPU oder der RAM — es ist dein VRAM (Video-RAM). Große Sprachmodelle sind gewaltige mathematische Strukturen, und damit sie in menschlich lesbarer Geschwindigkeit antworten, müssen sie im Speicher der GPU leben.
Ich habe das Glück, mit einer NVIDIA RTX 4070 Ti Super zu arbeiten, da ich Cutting-Edge-Gaming liebe. Sie ist zwar keine A100 der Enterprise-Klasse, aber sie hat ein entscheidendes Merkmal, das für mich alles veränderte: 16GB VRAM.
Der „Aha!“-Moment: Gemma laufen lassen
Lauf · Gemma-26B (a4b) in 16GBDer Moment, in dem die Reise für mich „echt“ wurde, war, als ich Gemma-26B (die a4b-Variante) erfolgreich auf meine 4070 Ti Super lud. Ein Modell dieser Größe — ein Modell mit 26 Milliarden Parametern — auf Consumer-Hardware laufen zu lassen, fühlt sich wie Magie an.
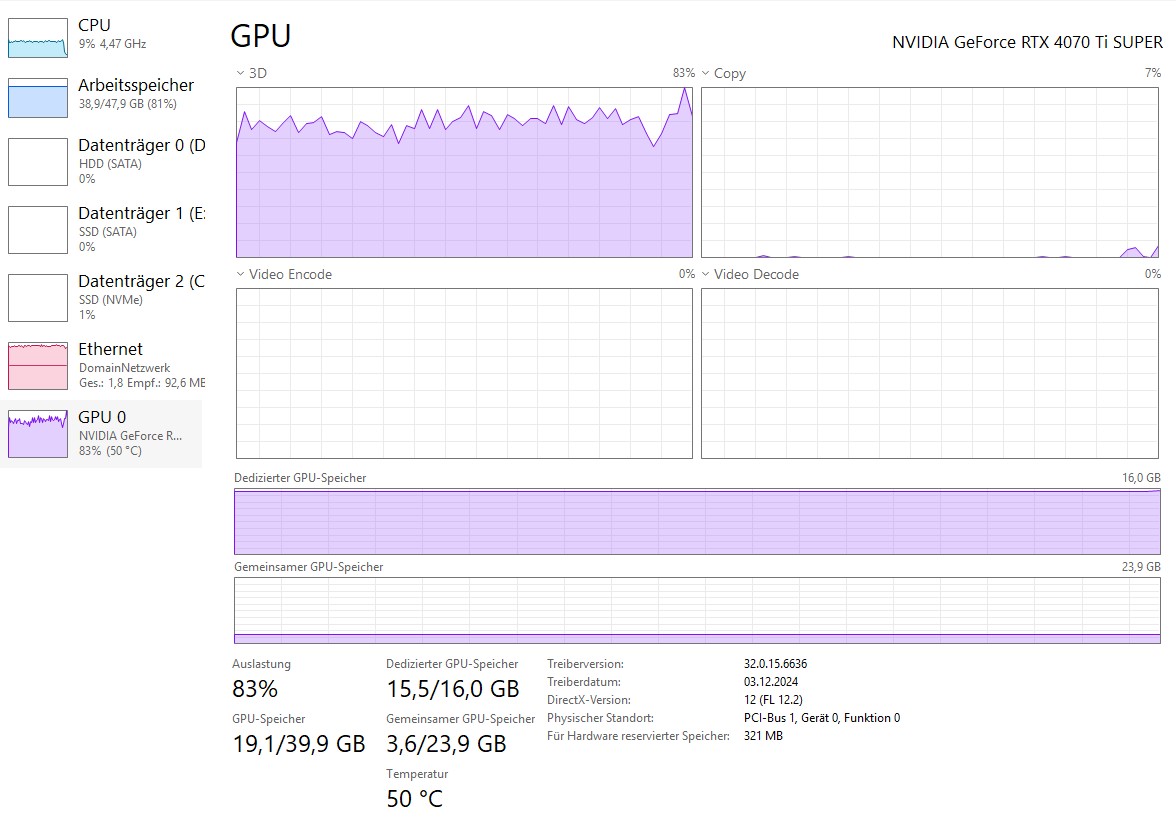
Wegen der Art, wie das Modell quantisiert (komprimiert) ist, passt es bequem in mein 16GB-VRAM-Limit. Den Text über den Bildschirm strömen zu sehen, vollständig von meinem eigenen Strom und meinem eigenen Silizium gespeist, war ein tiefgreifender Perspektivwechsel.
Keine Daten an Dritte. Keine Nutzungslimits. Keine Abostufen. Nur ich, meine GPU und das Modell.
Eine gewisse Gelassenheit
Behalten · deine Daten auf deiner PlatteMit lokalem Hosting kommt eine gewisse Gelassenheit. Es werden keine Daten an ein Drittunternehmen gesendet, um dessen nächste Iteration zu trainieren. Es gibt keine „Nutzungslimits“ oder „Abostufen“. Es gibt nur mich, meine GPU und das Modell.
Es ist ein anderes Verhältnis zum Werkzeug — näher daran, ein Instrument zu besitzen, als einen Dienst zu mieten. Sind die Gewichte erst einmal auf der Platte, ist das Internet optional.
Immer noch ein Schüler
Lernen · Quantisierung, Kontext, VRAMIch bin in diesem Feld noch sehr ein Schüler. Ich lerne über Quantisierung (wie wir Modelle schrumpfen), Kontextfenster (wie viel sich ein Modell merken kann) und die heikle Balance, große Gewichte in begrenztem VRAM unterzubringen.
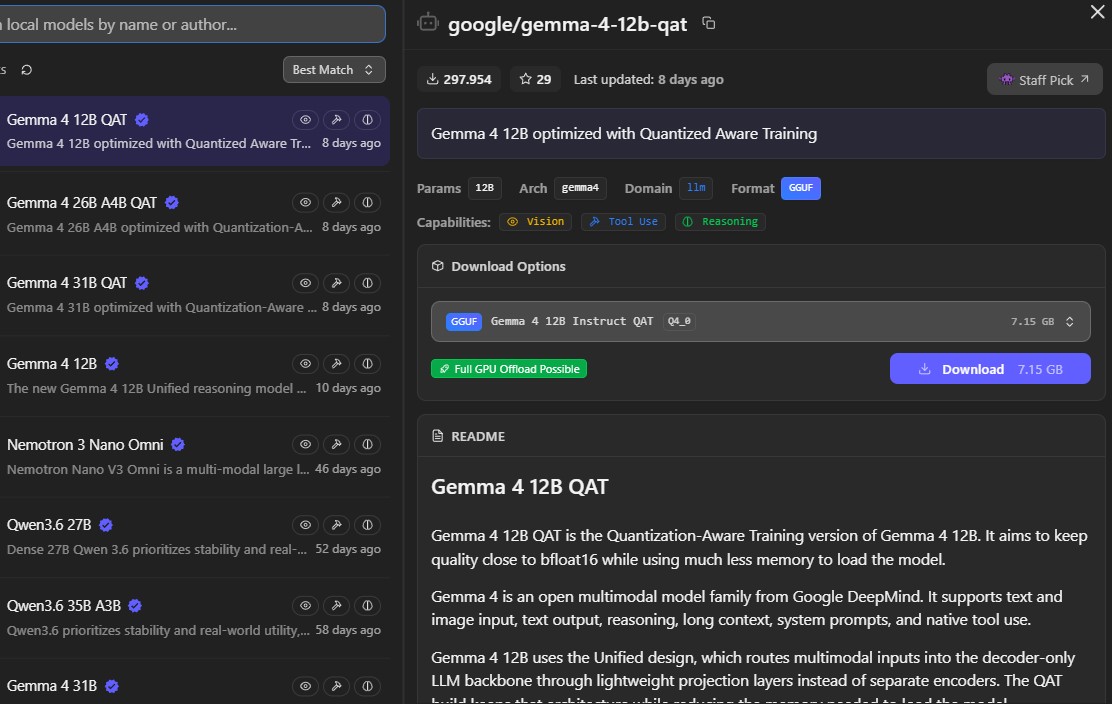
Das Ziel ist nicht bloß, eine coole Tech-Demo auf dem Desktop zu haben; es ist, einen privaten, intelligenten Assistenten zu bauen, der mir wirklich gehört.
Wenn du eine GPU mit ordentlichem VRAM hast, ist mein Rat einfach: Lade LM Studio herunter, such ein Modell und fang an zu spielen. Die Cloud ist großartig — aber am Rand liegt die echte Freiheit.